从大数据到图计算-Graph On BigData
author: 彭志伟
背景
自2003年Google的三篇大数据领域经典论文GFS、MapReduce和BigTable发表以来,大数据领域取得了长足的发展。尤其是开源大数据领域各种优秀的开源大数据引擎层出不穷,先后出现了Hadoop、Hive、Storm、Spark、Flink以及Presto等多种优秀的开源项目。从应用场景上覆盖了离线计算、流式计算、OLAP查询以及流批一体等多种计算形态,针对大数据的处理技术日益完善和多样化。
这些大数据引擎主要处理的是表模型的数据,即将要处理的数据以表模型来建模,然后进行加工处理。表模型虽然相对简单,易于理解,然后也存在局限性,尤其是在处理复杂关系的运算和表达上存在着比较大的困难。表模型主要通过Join的方式来处理表之间的关联关系,Join的方式会带来大量的shuffle,增加运行资源。尤其是当关联度数比较高时,Join方式的弊端会更加明显。另外对于复杂关系的描述比如最短路径、k-hop等通过表模型语言SQL也很难表达。
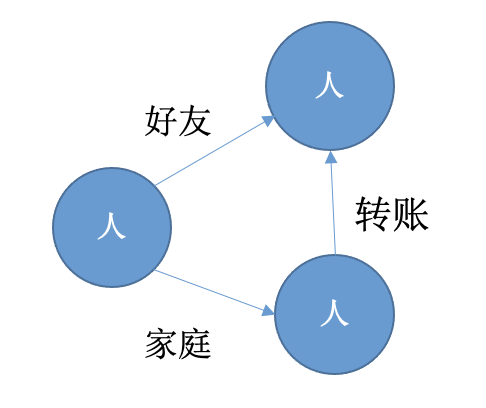
图模型作为一种以点和边作为基本单元定义的数据模型天然可以描述关联关系。在图模型里面以点代表实体,以边代表关系。比如在人际关系图里面,每一个人可以用一个点来表示,人和人之间的关系通过边来表示,人与人之间可以存在各种各样的复杂关系,这些关系都可以通过不同的边来表示。基于图模型一方面可以很好的描述复杂关系以及复杂关系的运算,另外一方面图的存储模型天然存储点边关联关系,在计算层面可以获得更好的计算性能。
实时图计算引擎-GeaFlow
在蚂蚁金融风控场景下存在大量复杂关系的处理,比如反套现系统里面需要查找多跳的转账关系来检查是否存在环路,判断用户是否存在套现行为;日志归因分析场景下需要分析用户的行为路径等。这些场景一方面关联关系复杂,另外一方面计算时效性要求高,业务往往需要分钟级甚至秒级延迟; 同时图数据规模大,可以达到千亿甚至万亿点边规模。传统的大数据引擎无法满足以上需求,比如Spark GraphX具备大规模图数据处理的能力,但主要偏离线计算场景,无法满足时效性要求;Flink具备强大的实时计算能力,但是很难处理多跳的实时Join关联计算,尤其是数据规模大的场景。
面对这些问题和挑战,蚂蚁图计算团队从实际问题出发,经过多年探索和实践,实现了一套分布式实时图计算引擎GeaFlow(品牌名TuGraph-Analytics)。GeaFlow以图模型作为基本的数据模型,在图模型基础之上定义了一套图计算的编程接口,同时和流式处理能力相结合,实现了流式图计算的能力。在DSL语言层面,GeaFlow将表处理语言SQL和图查询语言ISO/GQL相结合,实现了图表一体的数据分析能力。通过GeaFlow流图计算的能力,很好的解决了金融场景下面临的大规模数据复杂关联关系实时计算的问题。
GeaFlow整体架构
GeaFlow整体架构从上往下包含以下几层:
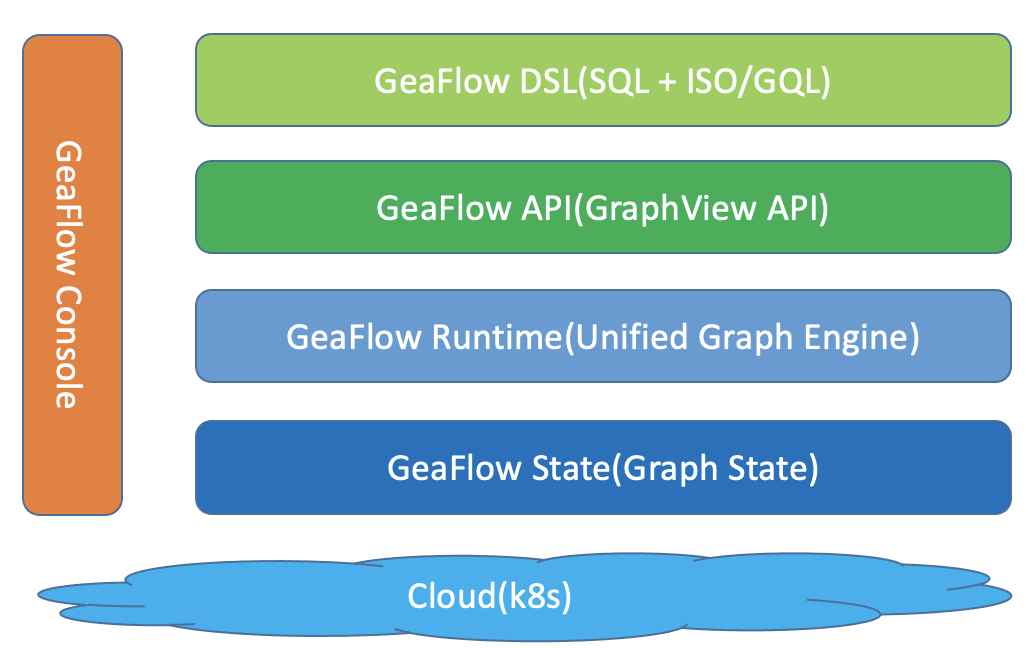
- GeaFlow DSL GeaFlow对用户提供图表融合分析语言,采用SQL + ISO/GQL方式.用户可以通过类似SQL编程的方式编写实时图计算任务.
- GraphView API GeaFlow以GraphView为核心定义的一套图计算的编程接口,包含图构建、图计算以及Stream API接口.
- GeaFlow Runtime GeaFlow运行时,包含GeaFlow图表算子、task调度、failover以及shuffle等核心功能.
- GeaFlow State GeaFlow的图状态存储,用于存储图的点边数据.同时流式计算的状态如聚合状态也存放在State中.
- K8S Deployment GeaFlow支持K8S的方式进行部署运行.
- GeaFlow Console GeaFlow的管控平台,包含作业管理、元数据管理等功能.
GeaFlow和大数据生态结合
图计算系统不是一个孤立的系统,必须和现有大数据生态结合,才能更好的解决大数据领域的问题。GeaFlow通过Connector插件的形式支持了和主流大数据生态的打通,比如Kafka/Hive/HDFS等。通过Connector插件,可以很容易将大数据生态的数据接入的到图计算系统中来。下面我们将以Hive为例介绍如何将数仓里的数据导入到GeaFlow图存储中,然后跑通一个图算法。
图定义
我们首先需要定义张图,使用Create Graph语法定义如下:
CREATE GRAPH IF NOT EXISTS friend (
Vertex person (
id bigint ID,
name varchar
),
Edge knows (
srcId bigint SOURCE ID,
targetId bigint DESTINATION ID,
weight double
)
) WITH (
storeType='rocksdb',
shardCount = 1
);
这张图定义包含点表person和边表knows. 点表person定义了点的属性信息和id字段,id字段唯一标识图里面的点,为点表的主键,通过ID 关键字来定义。边表knows里面定义好友关系,srcId为关系的起点,通过SOURCE ID关键字定义;targetId为关系的目标点,通过DESTINATION ID关键字定义。weight字段则为边的一个属性字段。一张图的点边或者边表可以包含零个或者多个属性字段。
Hive表定义
首先我们需要定义一张Hive点表和Hive边表, 表里面指定schema信息以及metastore uri等信息:
set geaflow.dsl.window.size = -1;
CREATE TABLE IF NOT EXISTS hive_person (
id BIGINT,
name VARCHAR
) WITH (
type='hive',
geaflow.dsl.hive.database.name = 'default',
geaflow.dsl.hive.table.name = 'user',
geaflow.dsl.hive.metastore.uris = 'thrift://localhost:9083'
);
CREATE TABLE IF NOT EXISTS hive_knows (
src_id BIGINT,
target_id BIGINT,
weight DOUBLE
) WITH (
type='hive',
geaflow.dsl.hive.database.name = 'default',
geaflow.dsl.hive.table.name = 'relation',
geaflow.dsl.hive.metastore.uris = 'thrift://localhost:9083'
);
GeaFlow是一个流式图计算引擎,数据源按照window size切分成一系列的window, 引擎会依次处理这些window的数据。如果window size设置为-1,则代表一个All Window,即一次全量处理所有数据。对于Hive这样的批数据源接口,需要设置window size为-1来处理。
构图
构图是将外部数据表的数据写入到图里面,可以通过Insert语句来完成。如下语句,分布将hive表里面的数据写入到friend图的person表和knows表里面,完成图数据的构建。
INSERT INTO friend.person(id, name)
SELECT
id, name
FROM hive_person
;
INSERT INTO friend.knows
SELECT src_id, target_id, weight * 10
FROM hive_knows
;
图计算
接下来是对构建好的图数据做图算法计算,我们以SSSP(单源最短路径)为例进行介绍:
CREATE TABLE IF NOT EXISTS result (
vid int,
distance bigint
) WITH (
type='file',
`geaflow.file.persistent.config.json` = '{\'fs.defaultFS\':\'namenode:9000\'}',
geaflow.dsl.file.path='/path/to/result'
);
-- 定义计算使用的图
USE GRAPH friend;
INSERT INTO result
CALL SSSP(1) YIELD (vid, distance)
RETURN vid, distance
;
首先需要定义一个结果表result来存放计算结果,然后通过USE GRAPH命令来设置当前计算用到的图。最后通过CALL语句来执行SSSP算法(其中SSSP算法的入参为起始点id), 并将计算结果写入结果表。
总结
本文首先介绍了图计算引擎GeaFlow产生的历史背景,然后介绍了GeaFlow如何和大数据生态整合。并通过一个例子介绍了如何将Hive的数据转换成图并在图上运行一个SSSP算法。
GeaFlow(品牌名TuGraph-Analytics) 已正式开源,欢迎大家关注!!!
欢迎给我们 Star 哦!
Welcome to give us a Star!
GitHub👉https://github.com/TuGraph-family/tugraph-analytics
微信群

请点击项目链接下方微信二维码添加微信用户群:https://github.com/TuGraph-family/tugraph-analytics