重磅发布!!!蚂蚁图团队开源高性能原生图存储系统CStore
作者:唐浩栋
CStore是一款专门为图分析场景而设计的原生图存储引擎,它采用了Rust语言编写,使用基于图的存储结构,针对图分析场景进行特定优化。CStore可以存储包含千亿级点和万亿级边的图数据,在蚂蚁集团内部的多场景使用中,已经积累了多年的经验,存储容量达到了PB级别。
图存储系统
百艺通,不如一艺精
在设计数据存储引擎时,需要考虑众多因素。例如,所应用的具体场景,是联机分析处理(OLAP)还是联机事务处理(OLTP);再如,数据存储方式的选择,内存、本地硬盘或分布式存储;还有就是存储数据的格式,像是文档、JSON,宽表,对象,键值对等。图存储引擎是诸多数据存储引擎中的一种,它专门用于图数据的存储。从DB-Engines网站的统计来看,Graph DBMS的热度从2014后一直领先其他类型数据库。
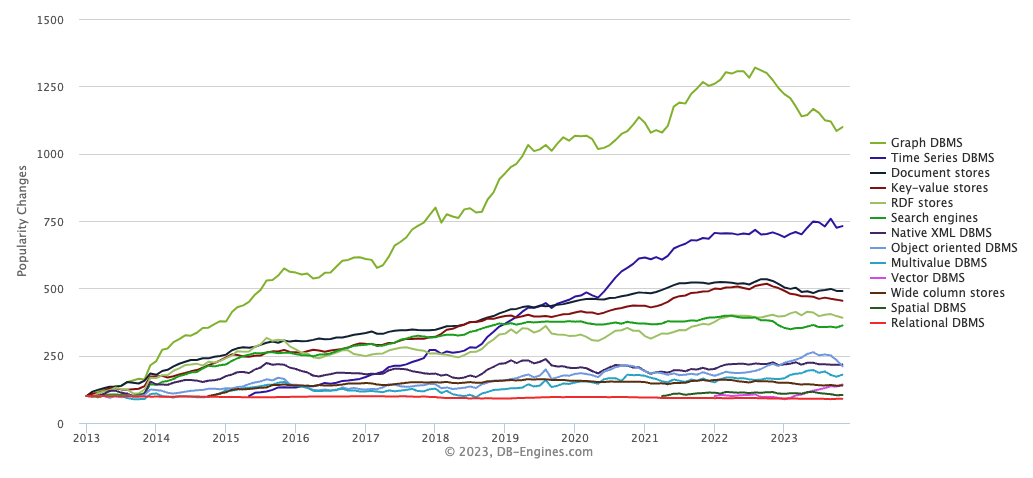
根据图数据存储方式的不同,现有的图存储引擎主要分为下面几大类:
- 基于链表,例如Neo4j。
- 基于Hash+链表,例如ArangoDB。
- 基于Key-Value键值,例如Titan/JanusGraph/HugeGraph。
- 基于传统关系型数据库,例如AgensGraph。
CStore基于Array+链表的方式存储数据,支持实时读写能力。为了提供更好的图分析能力,CStore把图元数据和属性分离存储,单独对元数据构建多级索引。CStore在存储方式和索引设计上都充分考虑到图语义,有效地结合图数据访问的特点,充分利用计算机硬件的优势,在蚂蚁内部多个场景中得到验证,取得很好的业务效果。 接下来从建模、存储、索引三个方面来介绍CStore作为原生图存储引擎的特点。
原生图建模
图形数据非常适用于描述复杂的网络关系。与其他存储格式相比较,图形数据具有自身的独特之处。举例来说,在 NoSQL 数据库中,Key-Value 数据库只包含 Key 和 Value 这两种元素,用户更容易理解和操作,并且存储引擎的设计也可以遵循一定的规则。另外,对于 DBMS(数据库管理系统)来说,实体关系模型必须按照一定的规范来进行设计,通常情况下,要求业务表的设计至少要符合第三范式,以此来消除数据冗余现象。CStore基于属性图来建模,属性图是由点,边,以及点和边上的属性组成的图,点数据中记录了起始点ID和图元数据(标签,时间戳),边数据记录了起始点ID和图元数据(终点ID,方向,标签,时间戳),每个起始点ID唯一确定一组点边数据。
点边数据进入到CStore之后,把点边起始点ID转化为从0开始的ID,这个过程称之为ID化。由于用户定义的起始点ID格式不固定,蚂蚁内部使用的起始点通常大于20bytes,转化为4个bytes ID后,可以极大减少索引内存消耗;另外规范化ID之后,CStore使用array来做主键索引,array的index为ID,查询效率为O(1)。
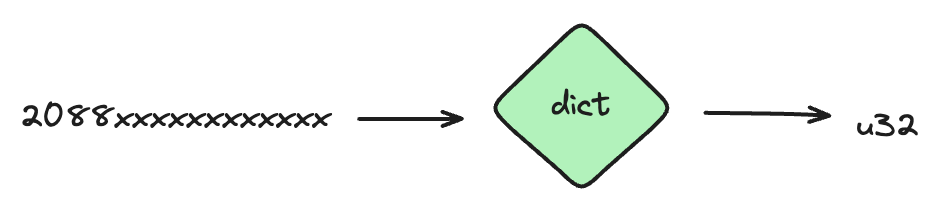
ID化之后,点边数据被序列化为PrimaryKey和GraphData,GraphData由SecondKey和Property组成。PrimaryKey记录点边ID,SecondKey记录图元数据,Property记录点边属性数据。
SecondKey编码格式如下,target id大小不固定,其他部分消耗20 bytes。write ts字段记录数据写入时间,被用于数据淘汰,sequence id记录了数据写入顺序,transaction和compaction都会用到。graph info记录是否是点,是否是入边,是否包含属性,标签,其他meta, 点边时间属性等信息。
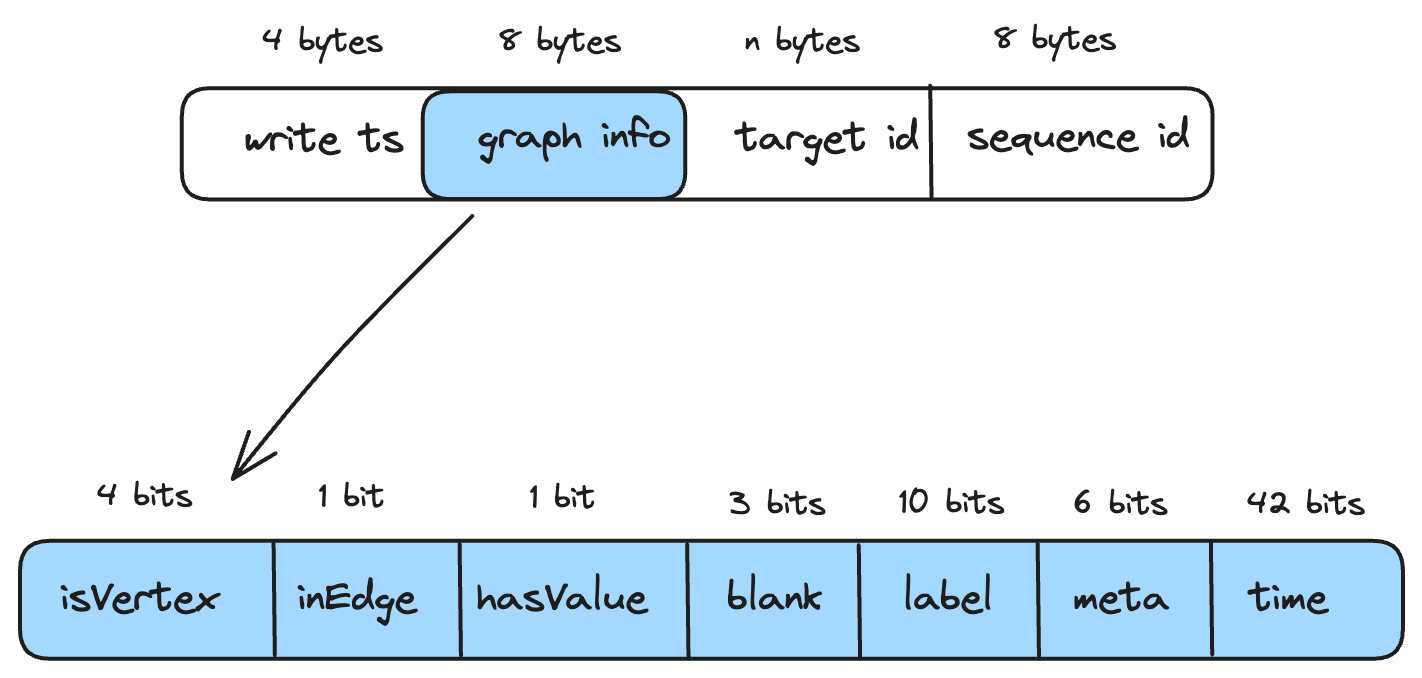
这样编码有两点好处:
- 点边数据变成CStore内部具有固定格式的二进制数据,有效减少内存消耗,方便后续数据写入磁盘;
- 图元数据被压缩到8字节,这样可以把更多的图信息放到索引侧,能够提前在索引侧过滤掉用户不需要的数据。
许多图形数据库会选择将点边数据编码为键值对的形式存储。相比之下,CStore是一款针对图分析场景而设计的存储引擎,目的是提供更快的分析能力。为了实现这一点,CStore会对经过编码后的图形信息建立多级索引。在下面的内容里,我们将讨论如何存储数据以及构建多级索引。
友好图存储
蚂蚁内部图数据的访问有以下几个特点。
- 通常相同起始点ID的点边数据大概率一起被访问;
- 相同类型, 时间的数据通常被一起访问;
- 用户点边数据的属性非常大,而点边元数据信息为固定结构且数据量不大;
- 点数据查询频率大于边数据。
CStore在设计存储结构的时候,结合上述特点,对特定场景进行优化。针对第一个特点,CStore尽可能的把具有相同的起始点ID的点边数据存储到物理上连续的存储空间。点边数据被序列化之后,数据首先被写入GraphData Segment,它为内存数据结构,使用跳表来组成数据,维护了起始点ID到GraphData List的结构。 GraphData Segment主要有两个功能:
- 数据聚合。把相同的src_id的点边数据聚合到一起存储。
- 排序。按照用户指定顺序把相同src_id的点边数据排序,用于构建二级索引。
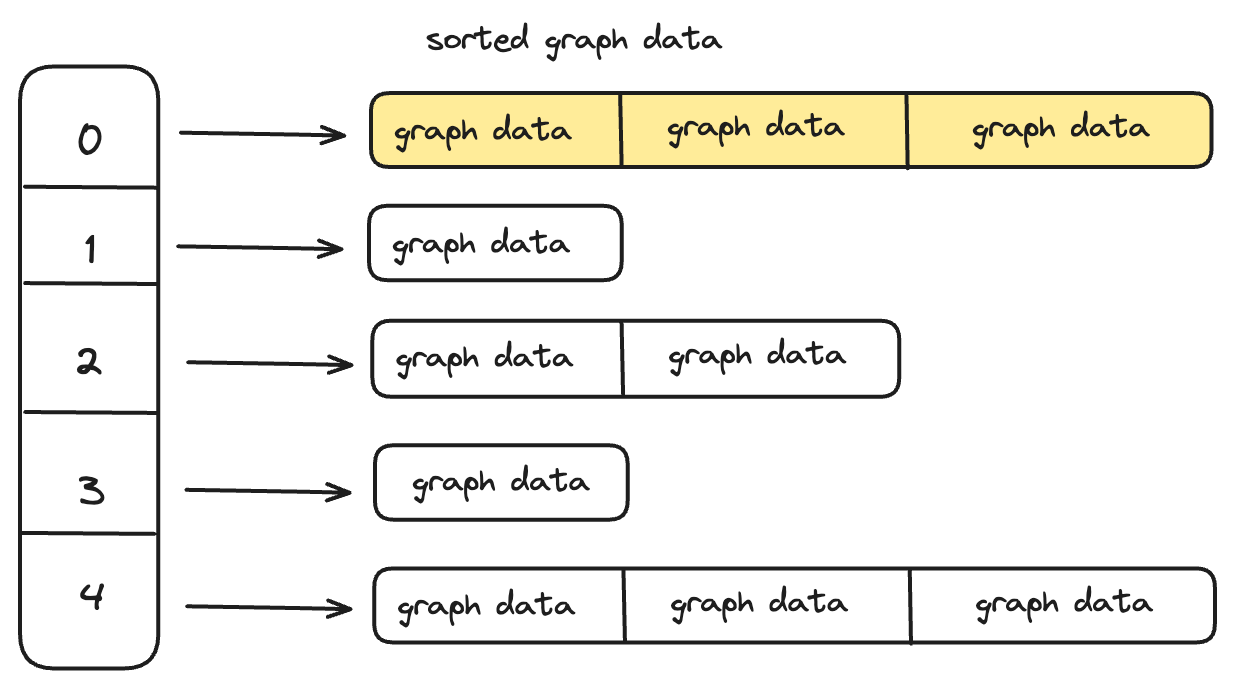
GraphData Segment到达阈值之后被刷入到磁盘,数据被刷入到磁盘之前,把具有相同类型,写入时间(通常以天为单位)的数据作为一个分区写入到连续的物理存储空间,每个分区之间数据互相独立。
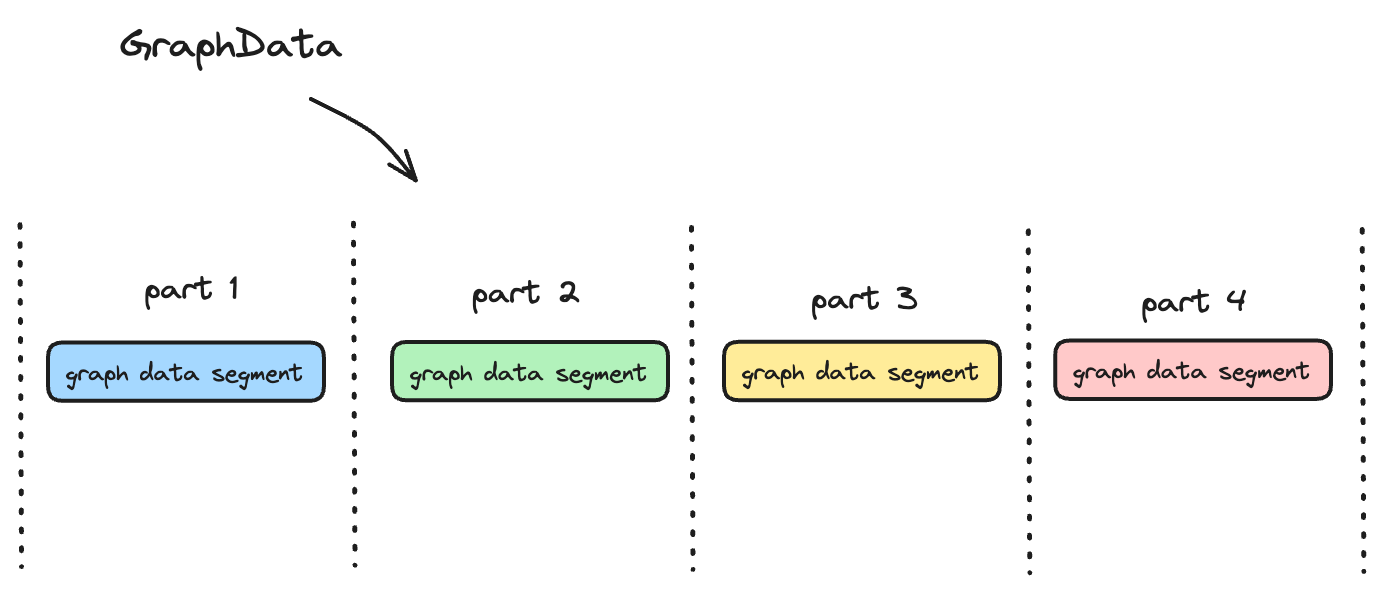
再者根据点边数据属性大而元数据固定的特点,CStore采用了属性分离的架构,把图属性和图元数据分离存储到不同的物理存储空间。一方面对于图元数据单独加索引能够加速图查询性能,另外一方面属性分离也能够减少数据compaction的读写放大开销。
另外CStore还支持用户配置点边数据存储到不同的存储介质,点边数据在物理上隔离。点边数据的访问频率在不同的场景有所不同,分离存储能够进一步优化数据访问性能,提前过滤掉不需要的数据,减少数据读放大。
高效图索引
CStore具有高效的图数据检索能力,支持多维度索引,不仅提供针对图元数据的分区索引,主键索引和二级索引,还支持针对点边属性的全文索引,可以根据指定的条件快速定位和返回数据。
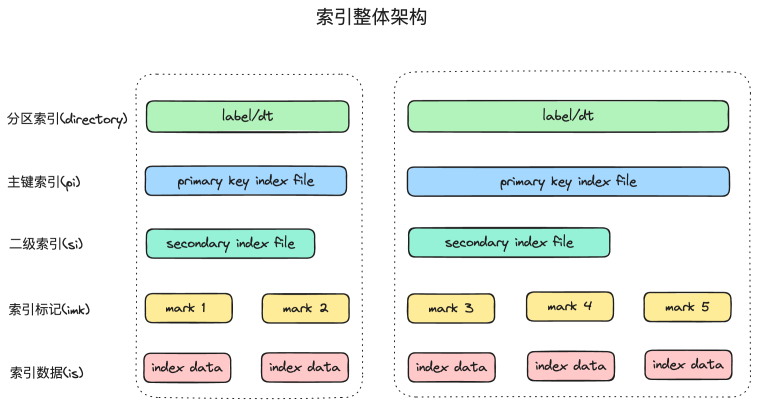
GraphData Segment写入到磁盘之前,把相同起始点ID的GraphData根据用户指定的顺序排序,然后把排序好的SecondKey构建索引,把排序好的Property直接写入到属性文件(记为vs文件)。
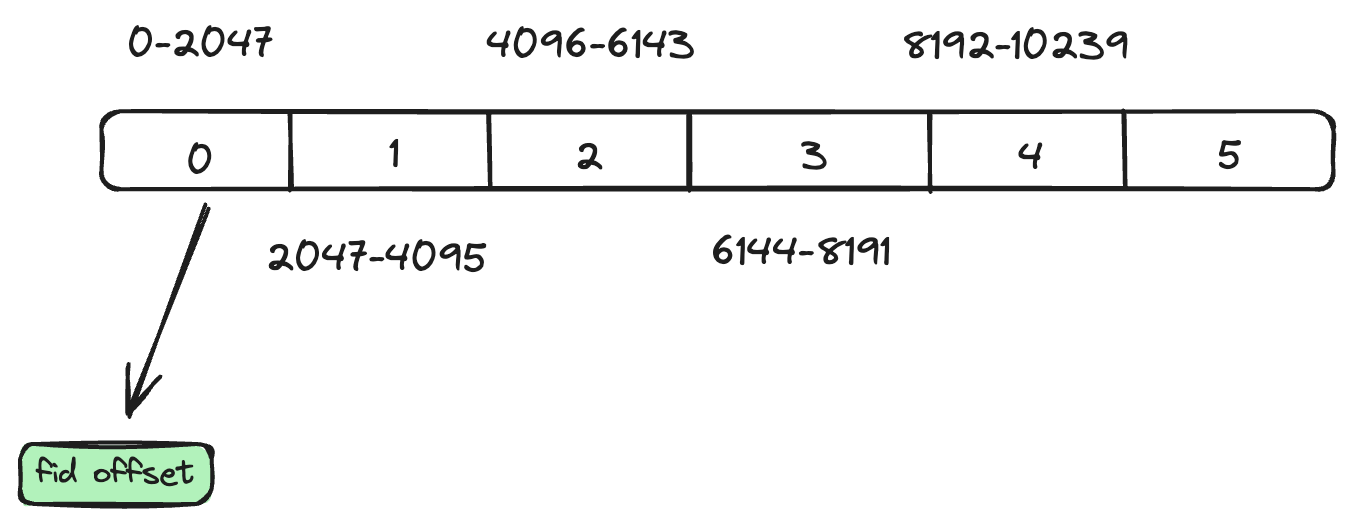
CStore的分区索引对应到磁盘中某个目录,不同的分区数据落在不同的目录。主键索引是稀疏索引,默认索引间隔为2048,目前仅支持以起始点ID构建主键,主键索引常驻内存。通过主键索引,可以快速定位到属性存储的文件id和offset。
二级索引包括min max索引,bloom filter索引等,用于快速判断某个稀疏索引块是否包含某个主键。min max索引记录某个索引块的上界和下界,bloom filter记录索引块的主键。
对于热点数据,二级索引做了特殊支持,比如一个起始点ID对应了10亿条边,如果没有索引,需要把满足min max和bloom filter索引的所有边读到内存过滤一次,返回用户指定的数据。为了加速这种场景,CStore对点边类型,指向,写入时间加了二级索引。比如用户只想要读取label为student,dt为2023-10-1数据,通过二级索引,首先过滤掉所有label非student的数据,然后过滤掉dt非2023-10-1的数据,可以极大减少数据读开销,提升用户查询性能。

构建完索引,数据写入到索引文件(记为is文件),is文件按照LSM-Tree结构组织,key为主键索引中的index,value为索引block压缩后的数据。is文件内部对于key有序,第0层单个文件内部对于key有序,其他层文件间对于key有序。
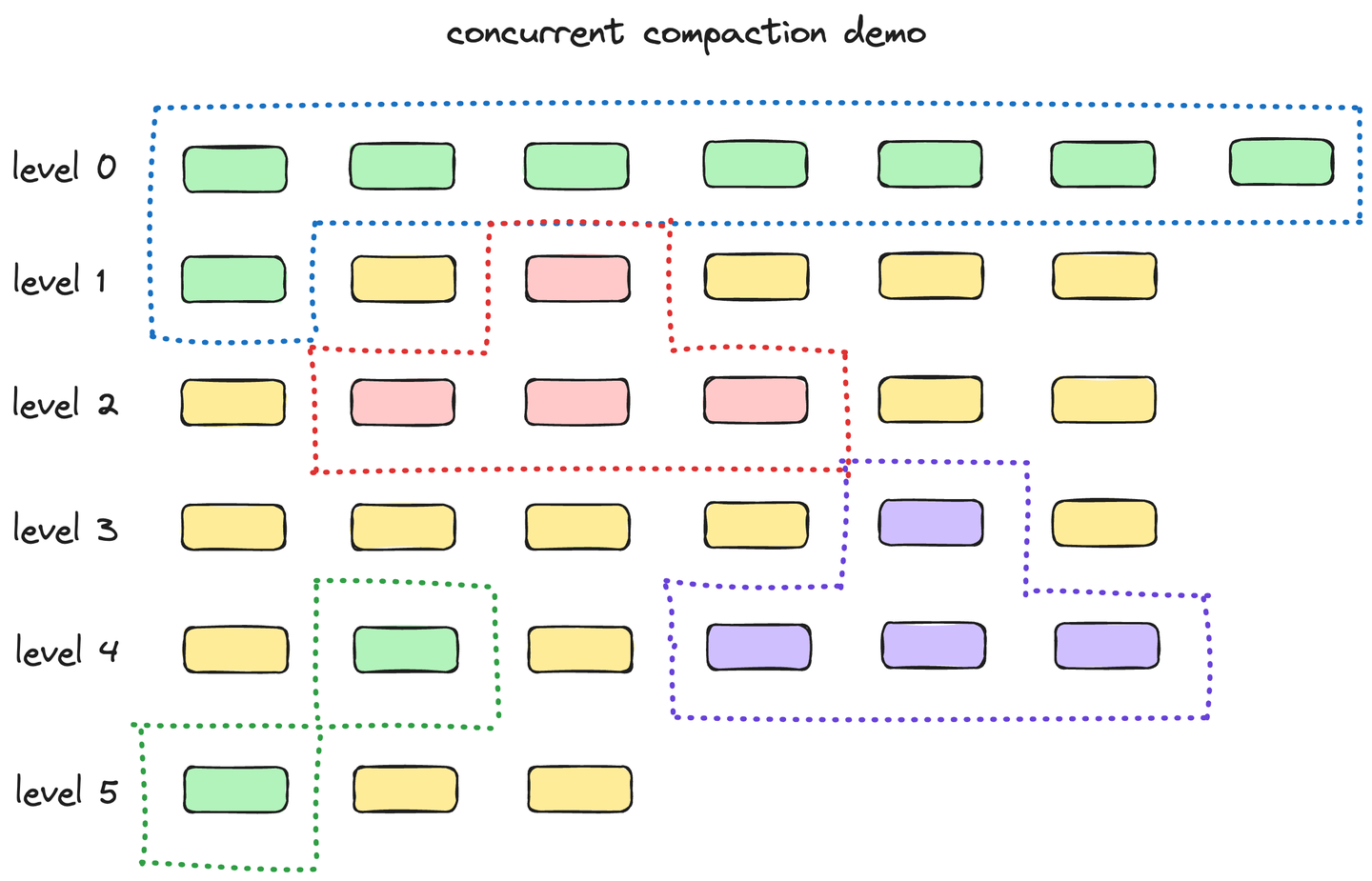
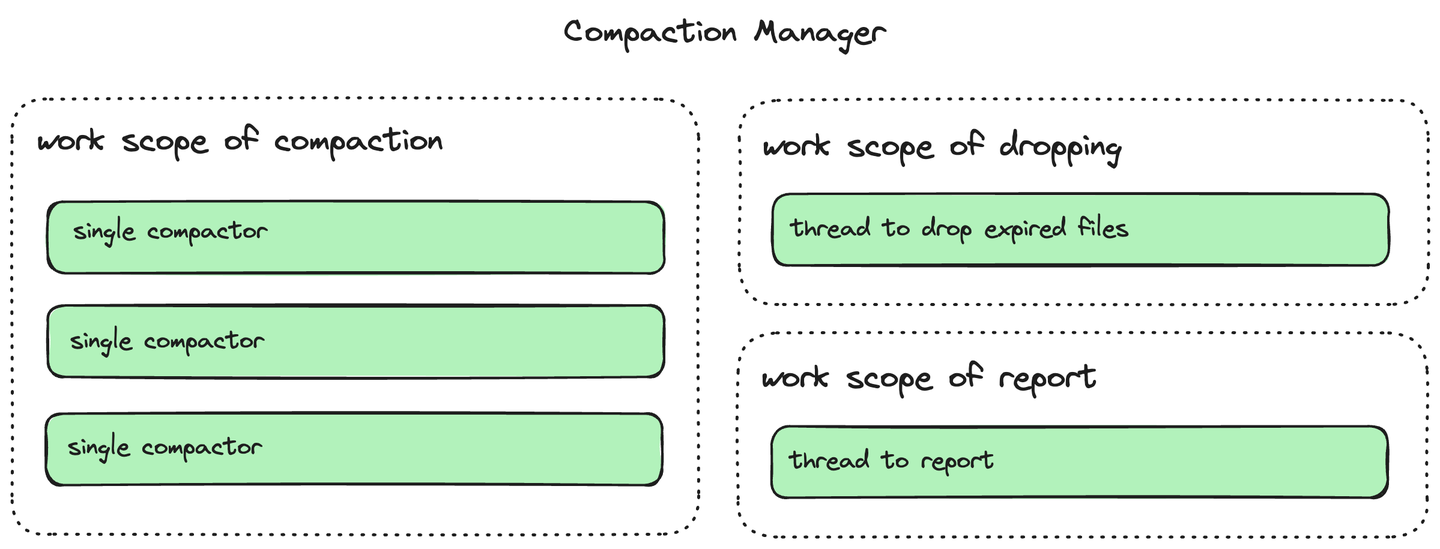
为了加快 LSM-Tree compact的性能,CStore 支持单层的多线程compact。在示意图中,每一个单独的compactor都代表一个compact工作线程。不同的compactor线程和compact清理线程(负责清理被compact的文件)将会并行执行。
以下是单个compactor内部运作过程的示意图,其中包括四个关键步骤:
- 计算各层次得分并选择其中最高的;
- 收集需要compact的文件;
- 将上述收集到的文件进行compact并生成新的文件;
- 最后一步是将新的文件更新至 LSM-Tree及内存索引中。
编译构建
单独编译CStore代码需要提前准备Rust和C++工具链。
# install rust.
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# install nightly toolchain.
rustup update && rustup toolchain install nightly && rustc --version
# install other dependencies.
yum install make gcc gcc-c++ protobuf-devel protobuf clang
下载TuGraph Analytics代码后,执行以下命令编译CStore源代码:
git clone https://github.com/TuGraph-family/tugraph-analytics.git
cd tugraph-analytics/geaflow-cstore && make build
执行make help可以查看makefile提供的功能,当前版本的功能和对应描述如下:
geaflow-cstore 0.1.0
Usage: make <target>
Targets:
build-dev Build the geaflow-cstore with dev version. Both <make build> and <make build-dev> work.
build-release Build the geaflow-cstore with release version.
fmt Format the code by rustfmt.toml.
clippy Check statically code with clippy.
test-all Run all integration tests and unit tests, include ignored tests.
test Execute all the unit tests.
test-fn Use "make test-fn mod=<func_name>" to specify which function of test to run.
test-in Use "make test-in mod=<func_name>" to specify which target of integration tests to run.
bench-all Run all benches.
bench Use "make bench mod=<mod_name>" to specify which bench of mod to run.
doc Generate the document of geaflow-cstore and open it in html.
all Execute code style and static checks, release version compilation and tests in sequence.
update Update all the dependences to the newest version, include rust analyzer.
gen Generate the code described by proto.
features Use "make features mod=<id>" {0->[default] 1->[hdfs]} to set the env in ~/.cstore_buildrc.
clean Clean up the cargo cache.
version Show the version of geaflow-cstore.
help List optional commands.
未来规划
CStore已在蚂蚁集团内部具备多年大规模生产化经验,未来我们将不断迭代升级,提升系统性能。然而,在一些特定的情况下,我们认识到CStore还有进步的空间。在未来一至两年内,我们计划更加深入地探索优化图分析场景,支持图数据列式存储,图融合以及物化视图能力。同时,为了提高用户的体验度,我们也将引入remote compactor功能,以解决因compact而导致的资源竞争问题。
目前,CStore系统已全部开源到TuGraph Analytics仓库(geaflow-cstore模块),当前推送的代码涵盖了CStore的核心功能特性,仍有大量的增强功能还在整合中。TuGraph团队将持续投入图存储系统CStore的建设工作,也非常欢迎图计算和图存储的开发者一起参与进来,共同推进CStore的开源和演进。
总结
当下TuGraph Analytics项目已经内置了CStore JNI的依赖,你可以在高阶API任务中使用并体验CStore静态图存储系统,CStore动态图能力正在建设中,敬请期待。同时我们也非常欢迎图存储系统/Rust爱好者加入到CStore开源项目的建设中来。
相关资料:
- TuGraph Analytics:https://github.com/TuGraph-family/tugraph-analytics
- CStore JNI:https://mvnrepository.com/artifact/com.antgroup.tugraph/cstore-jni
GeaFlow(品牌名TuGraph-Analytics) 已正式开源,欢迎大家关注!!!
欢迎给我们 Star 哦!
Welcome to give us a Star!
GitHub👉https://github.com/TuGraph-family/tugraph-analytics
微信群

请点击项目链接下方微信二维码添加微信用户群:https://github.com/TuGraph-family/tugraph-analytics