TuGraph Analytics动态插件:快速集成大数据生态系统
作者:廖梵抒
介绍
插件机制介绍
插件机制为GeaFlow任务提供了外部数据源的集成能力扩展,GeaFlow支持从各类Connector中读写数据,GeaFlow将它们都识别为外部表,并将元数据存储在Catalog中。GeaFlow已有一些内置的插件,例如FileConnector,KafkaConnector,JDBCConnector,HiveConnector等。
GeaFlow也提供了动态插件的功能,用户可以通过Java SPI的方式自定义Connector,连接外部数据源,例如Kafka,Hive等,也可自定义实现不同的sink、source连接方式和逻辑,更多关于自定义插件的介绍,可参考开发手册中自定义Connector章节。同时,GeaFlow Conosole平台为用户提供了插件管理的功能。在Console中,插件属于一种资源类型,用户可以通过白屏化的方式在Console上注册自定义的Connector插件,并在DSL任务或创建表时使用自定义的插件。
插件模型设计

- GeaflowPlugin: 插件模型。
- GeaflowPluginType: 插件(数据源)类型(KAFKA、HIVE、JDBC、FILE等)。
- GeaflowPluginCategory: 插件种类(图、表、文件等)。
- GealfowPluginConfig: 插件配置。
- GealfowJarPackage: jar包。
上文所述中,目前支持用户自定义Connector插件种类为TABLE,即可在表配置中使用,作为表的输入或输出源,其插件类型为用户自定义。
除此之外,在GeaFlow Console中,插件的概念更为广泛,还包含了一些系统级的插件,是GeaFlow作业运行所依赖的外部系统,例如运行时元信息插件(RUNTIME_META)、指标系统插件(METRIC)、外部文件系统插件(REMOTE_FILE)、外部图存储系统插件(DATA),如下列表所示。由插件类型和插件种类可唯一确定一个插件,而插件类型和插件种类是多对多的关系,一个种类可能有多种类型,例如REMOTE_FILE种类的插件,其类型可以是LOCAL、DFS、OSS,对应了不同的外部存储系统。

插件引用解析
解析dsl任务中使用的插件是使用代理的方式调用引擎的解析接口,通过Calcite解析得到dsl文本中的信息,其主要分为4步:
- 解析DSL中表with参数中定义的插件。
- 解析DSL中使用的表绑定的插件。
- 获取引擎自带的插件列表。
- 将1和2中的结果进行合并,过滤引擎自带的插件,得到最终dsl任务中用户使用的插件列表。

Demo演示
插件开发
自定义Collector
自定义Collector需要实现TableReadableConnector或TableWritableConnector接口,分别是获取数据输入和输出源。 本例子中,在原来的FileTableConnector基础上,扩展了为每条数据增加前缀或后缀的功能。其中MyFileSource可在读取数据时,在每条数据前加一个自定义前缀,而MyFileSink可在写入每条数据时,在其之后加一个自定义后缀。
public class MyFileConnector implements TableWritableConnector, TableReadableConnector {
@Override
public TableSource createSource(Configuration configuration) {
return new MyFileSource();
}
@Override
public TableSink createSink(Configuration configuration) {
return new MyFileSink();
}
@Override
public String getType() {
return "myFileType";
}
}
public class MyFileSource extends FileTableSource {
private static final Logger LOGGER = LoggerFactory.getLogger(MyFileSource.class);
private String suffix;
@Override
public void init(Configuration tableConf, TableSchema tableSchema) {
super.init(tableConf, tableSchema);
this.suffix = tableConf.getString("geaflow.dsl.mysource.suffix");
if (suffix == null) {
suffix = "mySourceSuffix";
}
LOGGER.info("init table source with tableConf: {}", tableConf);
}
@SuppressWarnings("unchecked")
@Override
public <T> FetchData<T> fetch(Partition partition, Optional<Offset> startOffset,
long windowSize) throws IOException {
FileTableSource.FileOffset offset = startOffset.map(value -> (FileTableSource.FileOffset) value)
.orElseGet(() -> new FileTableSource.FileOffset(0L));
FetchData<T> tFetchData = fileReadHandler.readPartition((FileSplit) partition, offset, (int) windowSize);
Iterator<T> dataIterator = tFetchData.getDataIterator();
Iterator<T> newIterator = (Iterator<T>) Iterators.transform(dataIterator, e -> suffix + "_" + e);
return FetchData.createBatchFetch(newIterator, tFetchData.getNextOffset());
}
}
public class MyFileSink extends FileTableSink {
private String suffix;
private static final Logger LOGGER = LoggerFactory.getLogger(MyFileSink.class);
private String separator;
private StructType schema;
@Override
public void init(Configuration tableConf, StructType structType) {
super.init(tableConf, structType);
this.separator = tableConf.getString(ConnectorConfigKeys.GEAFLOW_DSL_COLUMN_SEPARATOR);
this.schema = Objects.requireNonNull(structType);
this.suffix = tableConf.getString("geaflow.dsl.mysink.suffix");
if (suffix == null) {
suffix = "mySinkSuffix";
}
}
@Override
public void write(Row row) throws IOException {
Object[] values = new Object[schema.size()];
for (int i = 0; i < schema.size(); i++) {
values[i] = row.getField(i, schema.getType(i));
}
StringBuilder line = new StringBuilder();
for (Object value : values) {
if (line.length() > 0) {
line.append(separator);
}
line.append(value);
}
line.append("_").append(suffix);
LOGGER.info("sinkLine {}", line);
writer.write(line + "\n");
}
}
注册插件
GeaFlow使用ServiceLoader的方式读取所有的Connectors,需要在项目/resources/META-INF/services目录下,增加配置文件,文件名为com.antgroup.geaflow.dsl.connector.api.TableConnector。
文件内容为定义的Connector的全类名,如:
com.connector.myconnector.MyFileConnector
准备测试数据
在项目 /resources/data 目录中创建数据文件data1,便于后续测试
1,"tom",15
2,"cat",20
3,"anny",23
4,"alice",21
打包项目
最后,将maven项目进行打包,得到插件的jar包。
插件使用与管理
新增插件
在GeaFlow Console页面,“插件管理”模块中新增插件,填写插件名称方便管理,上传JAR包。其中“插件类型”字段需要和JAR包中自定义Connector#getType方法返回的值一致,并不能和已有插件重名。

创建表
创建source表,在参数配置中,选择类型为自定义的插件类型,并填写相应的参数(如输入表数据路径,自定义的suffix)。

创建sink表:
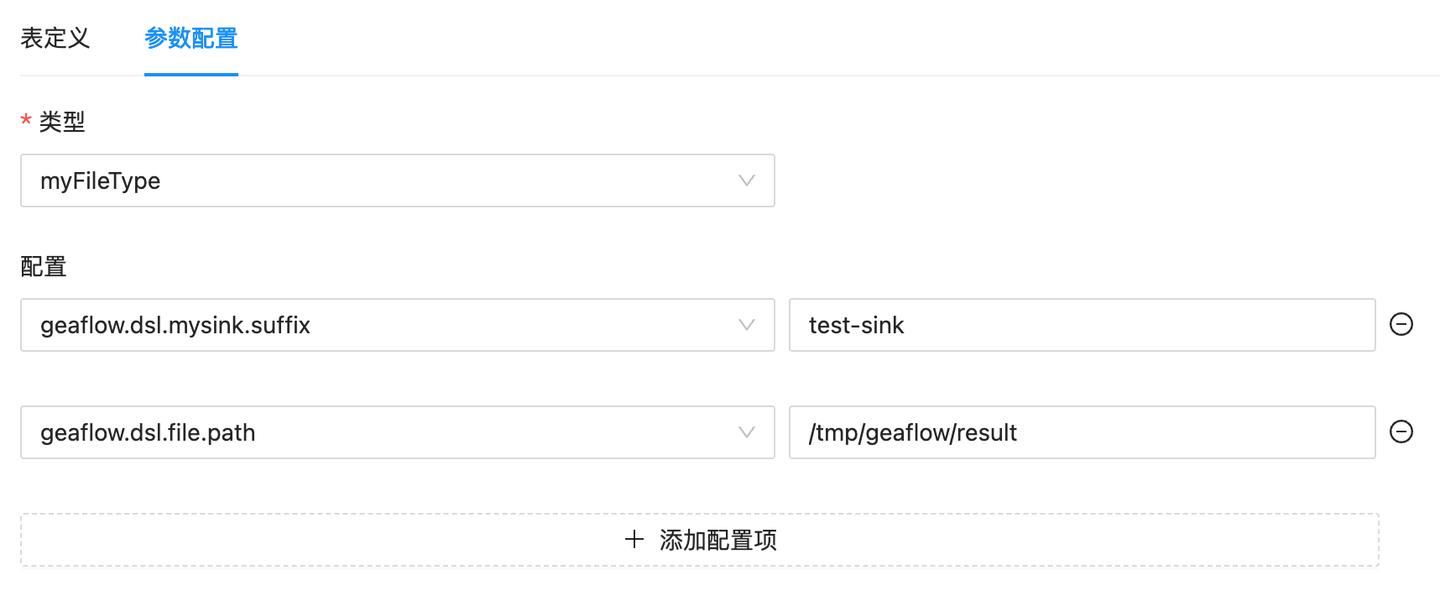
提交任务
创建dsl任务,直接在dsl中使用之前创建的source表和sink表。
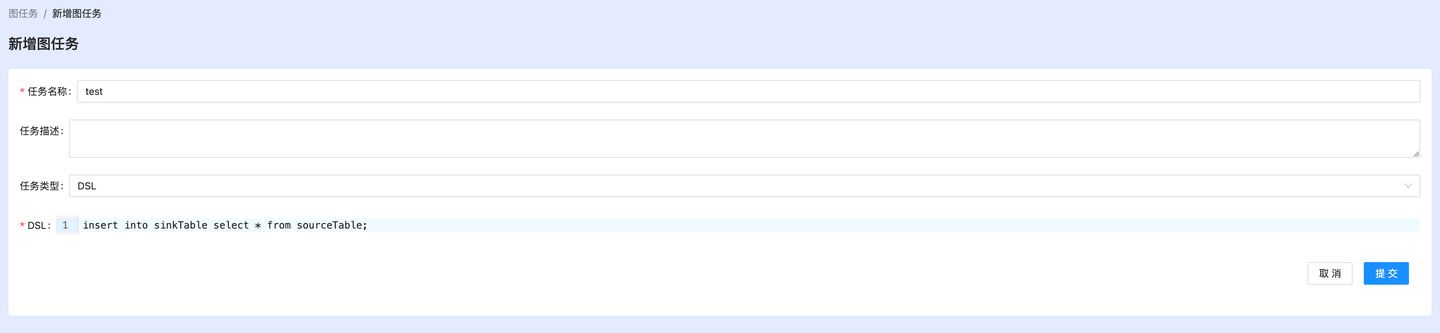
insert into sinkTable select * from sourceTable;
发布,提交作业后,在容器的/tmp/geaflow/result目录下,找到结果输出文件, 可看到输出数据中有插件中添加的suffix,表示自定义插件运行成功。
test-source_1,"tom",15_test-sink
test-source_2,"cat",20_test-sink
test-source_3,"anny",23_test-sink
test-source_4,"alice",21_test-sink
至此,我们就成功使用GeaFlow实现了自定义Connector插件!是不是超简单!快来试一试吧!
GeaFlow(品牌名TuGraph-Analytics) 已正式开源,欢迎大家关注!!!
欢迎给我们 Star 哦!
Welcome to give us a Star!
GitHub👉https://github.com/TuGraph-family/tugraph-analytics
微信群

请点击项目链接下方微信二维码添加微信用户群:https://github.com/TuGraph-family/tugraph-analytics